“Yapay Zekâ ile Uygulama Geliştirip Köşeyi Dönme” Hayaliniz Suya Düşebilir

Yeni bir araştırma, mevcut yapay zekâ araçlarının yazılım geliştirme ve hata çözme mevzularında yeterince iyi olmadığını ortaya çıkardı.
OpenAI, Anthropic ve benzeri yapay zekâ şirketlerinin geliştirdiği modeller artık yazılım geliştirme süreçlerinde kullanılmaya başlandı fakat bu alanda hevesi olanlar için belirtmek gerek, görünüşe bakılırsa daha geliştirilmesi ihtiyaç duyulan fazlaca şey var.
Google CEO’su Sundar Pichai, şirket içindeki yeni kodların %25’inin yapay zekâ tarafınca üretildiğini belirtmişti. Meta CEO’su Mark Zuckerberg de benzer planlamaları bulunduğunu söylemişti.
Yapay zekâlar hâlâ hataları çözmekte başarısız
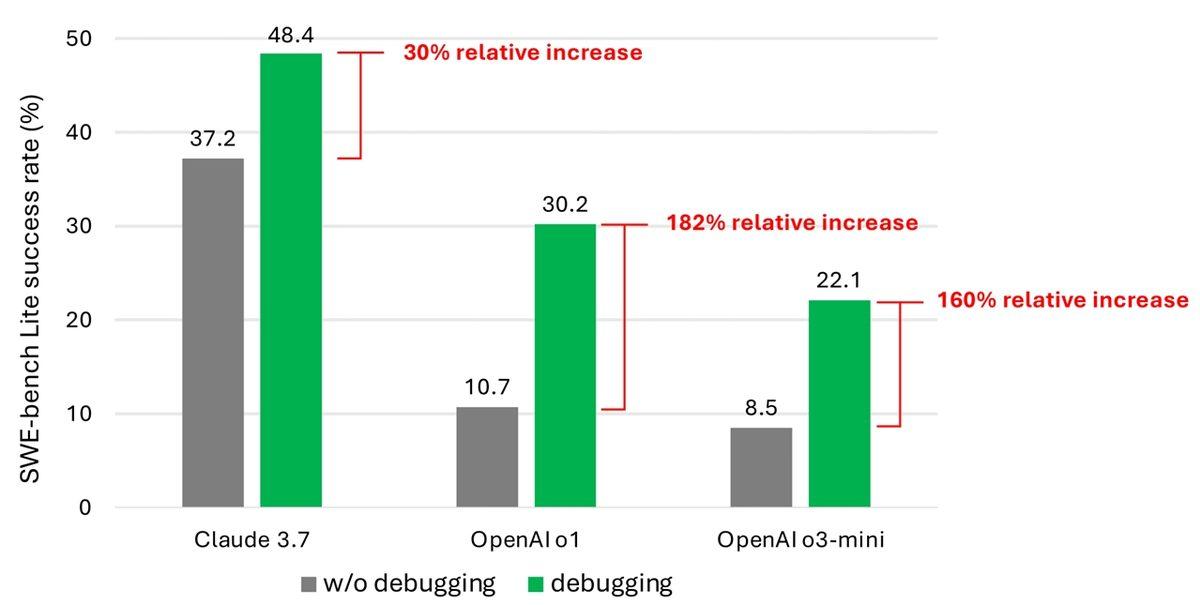
Fakat Microsoft Research tarafınca meydana getirilen yeni bir araştırma, bu modellerin yazılım hatalarını düzeltmede hâlâ yetersiz kaldığını ortaya koydu. SWE-bench Lite adlı testte, OpenAI’ın ve Anthropic’in ileri düzey modelleri, sunulan 300 hata düzeltme görevinden çoğunu çözemedi.
Claude 3.7 Sonnet en yüksek başarı oranına haiz model olsa da başarı oranı yalnızca %48,4’te kaldı. OpenAI’ın o1 modeli %30,2; o3-mini ise %22,1 başarı gösterdi.
Araştırmacılara bakılırsa bu düşük performansın temel sebepleri içinde modellerin hata ayıklama araçlarını verimli kullanamaması ve eğitim verilerinde gerçek insan hata ayıklama süreçlerinden yeterince yararlanamamaları yatıyor.
Yapay zekâ ile ilgili öteki içeriklerimiz:
Peki siz yapay zekâyı kodlama işleriniz için kullandınız mı? Deneyimlerinizi aşağıdaki yorumlar kısmından bizimle paylaşabilirsiniz.



